Review

ABSTRACT
For the past decade, artificial intelligence (AI) and its related technologies have made remarkable advances in marketing and business solutions based on AI-driven big data analysis of customer queries, and it, when coupled with bioinformatics, seemingly holds out great promise for use in healthcare. In reality, however, AI is still largely a buzzword when it comes to disease diagnosis and treatment. This review addresses the uncertainty of AI applications to disease diagnosis and treatment, not only pinpointing AI’s inherent algorithmic problems in dealing with non-patternable stochastic healthcare data, but also revealing the innate fallacy of identifying genetic mutations as a tool for genome-based personalized medicine. Finally, this review concludes by presenting some insights into future AI application in healthcare.
Key words: Artificial intelligence, machine learning, deep learning, bioinformatics, healthcare, genomic medicine, personalized medicine, reference genome, genetic variation.
INTRODUCTION
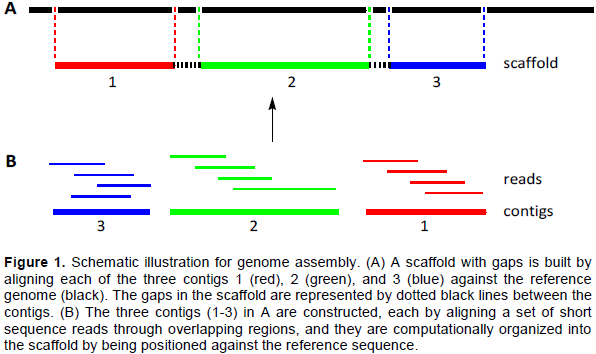
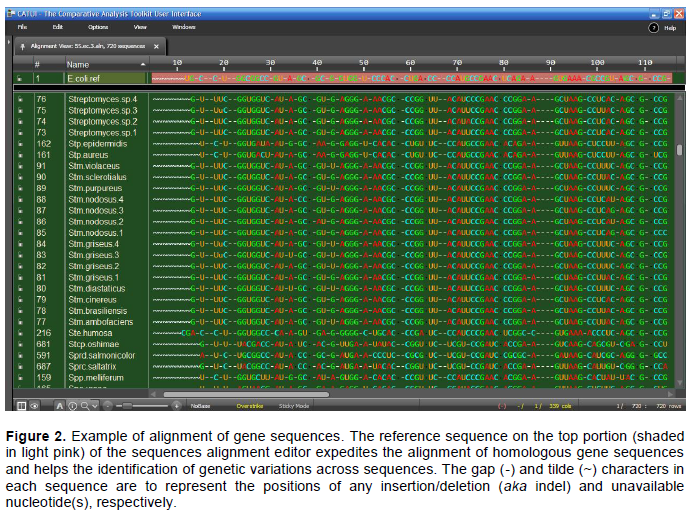
DISCUSSION AND CONCLUSIONS
CONFLICT OF INTERESTS
The author has not declared any conflict of interest.
REFERENCES
|
Acuna-Hidalgo R, Veltman JA, Hoischen A (2016). New insights into the generation and role of de novo mutations in health and disease. Genome biology 17(1):241. |
|
|
American Medical Association (AMA) (2018). Augmented intelligence in health care H-480.940. View |
|
|
Baker M (2012). The changes that count. Nature 482:257-262. |
|
|
Bartlett R, Morse L, Stanton R, Wallace N (2018). Consumer-lending discrimination in the era of FinTech. View |
|
|
Bini SA (2018). Artificial intelligence, machine learning, deep learning, and cognitive computing: What do these terms mean and how will they impact health care? Journal of Arthroplasty 33: 2358-2361. |
|
|
Bleicher A (2017). Demystifying the black box that is AI. Scientific American, August 9. |
|
|
Boddy A, Hurst W, Mackay M, El Rhalibi A, Baker T, Monta-ez CA (2019). An Investigation into Healthcare-Data Patterns. Future Internet 11(2):30. |
|
|
Burger MF, Lawrence MS, Demichelis F, Drier Y, Cibulskis K, Sivachenko AY, Sboner A, Esgueva R, Pflueger D, Sougnez C, Onofrio R (2011). The genomic complexity of primary human prostate cancer. Nature 470(7333):214. |
|
|
Canetti R, Cohen A, Dikkala N, Ramnarayan G, Scheffler S, Smith A (2019). From Soft Classifiers to Hard Decisions: How fair can we be?. In Proceedings of the Conference on Fairness, Accountability, and Transparency pp. 309-318. |
|
|
Challen R, Denny J, Pitt M, Gompels L, Edwards T, Tsaneva-Atanasova K (2019). Artificial intelligence, bias and clinical safety. BMJ Quality and Safety 28(3):231-237. |
|
|
Daley S (2018). Surgical robots, new medicines and better care: 17 examples of AI in healthcare. December 5. |
|
|
Davenport TH, Bean R (2018). The problem with AI pilots. July 26. View |
|
|
Ekblom R, Wolf JBW (2014). A filed guide to whole-genome sequencing, assembly and annotation. Evolutionary Applications 7:1026-1042. |
|
|
Esteva A, Kuprel B, Novoa RA, Ko J, Swetter SM, Blau HM, Thrun S (2017). Dermatologist-level classification of skin cancer with deep neural networks. Nature 542(7639):115-118. |
|
|
FDA (2013). Guidance for industry: electronic source data in clinical investigation. |
|
|
Ginsberg J, Mohebbi MH, Patel RS, Brammer L, Smolinski MS, Brilliant L (2009). Detecting influenza epidemics using search engine query data. Nature 457(7232):1012-1014. |
|
|
Hao K (2019). We analyzed 16,625 papers to figure out where AI is headed next. MIT Technology Review, January 25. |
|
|
International Human Genome Sequencing Consortium (IHGSC) (2004). Finishing the euchromatic sequence of the human genome. Nature 431:931-945. |
|
|
JASON (2017). Artificial intelligence for health and health care. View. |
|
|
Jiang F, Jiang Y, Zhi H, Dong Y, Li H, Ma S, Wang Y, Dong Q, Shen H, Wang Y (2017). Artificial intelligence in healthcare: past, present and future. Stroke and vascular neurology. 2(4):230-243. |
|
|
Kalis B, Collier M, Fu R (2018). 10 Promising AI applications in Health Care. Harvard Business Review, May 10. |
|
|
Knight W (2017). The dark secret at the heart of AI. MIT Technology Review, April 11. |
|
|
Larson J, Mattu S, Kirchner L (2016). Machine Bias. ProPublica, May 23. |
|
|
Lazer D, Kennedy R, King G, Vespignani A (2009). The parable of Google Flu: Traps in big data analysis. Science 343:1203-1205. |
|
|
Lee JC (2017). Are genes and their mutations responsible for disease? International Journal of Structural and Computational Biology 1(1):1-5. |
|
|
Lek M, Karczewski KJ, Minikel EV, Samocha KE, Banks E, Fennell T, O'Donnell-Luria AH, Ware JS, Hill AJ, Cummings BB, Tukiainen T (2016). Analysis of protein-coding genetic variation in 60,706 humans. Nature 536(7616):285-291. |
|
|
Mandal S, Greenblatt AB, An J (2018). Imaging intelligence: AI is transforming medical imaging across the imaging spectrum. IEEE Pulse 9(5):16-24. |
|
|
Mocanu DC, Mocanu E, Stone P, Nguyen PH, Gibescu M, Liotta A (2018). Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nature communications 9(1):2383. |
|
|
Murphy DR, Meyer AN, Vaghani V, Russo E, Sittig DF, Wei L, Wu L, Singh H (2018). Electronic triggers to identify delays in follow-up of mammography: Harnessing the power of big data in health care. Journal of American College Radiology 15:287-295. |
|
|
Ravi D, Wong C, Deligianni F, Berthelot M, Andreu-Perez J, Lo B, Yang GZ (2017). Deep learning for healthcare informatics. IEEE Journal of Biomedical and Health Informatics 21(1):4-21. |
|
|
Rosenblatt F (1958). The perception: A probabilistic model for information storage and organization in the brain. Psychological Review 65:386-408. |
|
|
Ross C (2019). FDA developing new rules for artificial intelligence in medicine. April 2. View. |
|
|
Schmidhuber J (2014). Deep learning in neural networks: An overview. Neural networks 61:85-117. |
|
|
Seo JS, Rhie A, Kim J, Lee S, Sohn MH, Kim CU, Hastie A, Cao H, Yun JY, Kim J, Kuk J (2016). De novo assembly and phasing of a Korean human genome. Nature 538:243-247. |
|
|
Sherman RM, Forman J, Antonescu V, Puiu D, Daya M, Rafaels N, Boorgula MP, Chavan S, Vergara C, Ortega VE, Levin AM (2019). Assembly of a pan-genome from deep sequencing of 910 humans of African descent. Nature Genetics 51(1):30-35. |
|
|
Simonite T (2014). IBM aims to make medical expertise a commodity. MIT Technology Review, July 21. |
|
|
Wang JY, Ho HY, Chen JD, Chai S, Tai CJ, Chen YF (2015a). Attitudes toward inter-hospital electronic patient record exchange: Discrepancies among physicians, medical record staff, and patients. BMC Health Services Research 15(1):264. |
|
|
Wang T, Birsoy K, Hughes NW, Krupczak KM, Post Y, Wei JJ, Lander ES, Sabatini DM (2015b). Identification and characterization of essential genes in the human genome. Science 350:1096-1101. |
|
|
Warwick W, Johnson S, Bond J, Fletcher G, Kanellakis PA (2015). A framework to assess healthcare data quality. The European Journal of Social and Behavioral Sciences 13(2):1730-1735. |
|
|
Yampolskiy RV, Spellchecker MS (2016). Artificial intelligence safety and cybersecurity: a timeline of AI failures. arXiv:1610.07997. |
|
Copyright © 2024 Author(s) retain the copyright of this article.
This article is published under the terms of the Creative Commons Attribution License 4.0


