ABSTRACT
Emergence of a hydrological forecasting model based on past records is crucial in solution of problem. In water resource and hydrology, to build the estimation model based upon the hydrological records, generally requires traditional time series analysis and modelling. Estimation can be done either by using Artificial Intelligence (AI) techniques, or by some traditional methods. The present work uses two data driven techniques, namely Artificial Neural Network (ANN), and Linear Genetic Programming (LGP) to estimate runoff by mixing the data of four gauging stations and evaluating on one catchment out of total five catchments namely Shivade, Shigaon, Gudhe, Amble and Belwadi catchments in the Krishna basin of India, and further the results are compared. The accuracy of model developed was judged by error measures criteria and by drawing time series and scatters comparative graphs. Three types of models are developed considering different combinations. All these models performed considerably well as seen from their performances. From the results it is found that ANN and LGP techniques performed equally well. However LGP performance is better as compared to ANN; as modelling approaches are examined, using the long-term observations of yearly river flow discharges.
Key words: Hydrological process, artificial neural network, linear genetic programming, forecasting runoff, meteorological parameters.
In hydrological process runoff estimation is perpetually based upon the observations of rainfall on the upper catchments which is very often supplemented by rainfall in the adjoining catchment. Addressing relationship to rainfall-runoff is most complex hydrological phenomena because of temporal and spatial variability of watershed and many numbers of variables are involved in this process. Hydrologists have attempted to understand this relationship to forecast stream flow and they have developed many models to stimulate this process. The flow of river can be predicted from Rainfall-Runoff models which use hydrological and climatic data or by stream flow models which utilize the hydrological data (Jain and Kumar, 2007).
A vast number of model structures usually a combination of linear and non-linear function have been
developed and implemented since early 1960s (Todini, 1998). Considering the use of the observational data and the description of the physical process the most commonly applied classification is empirical or black box model, conceptual or gray box model, and physically or white box models (Haykin, 1994).
An initial model based on measured rainfall runoff is called empirical or black box model. These models depend upon the observational data and also on the calibrated input-output relations without the description of the processes. (e.g. Transfer function models, unit hydrograph and empirical regression approaches). Second type models are conceptual or grey box models. In these models the basic processes, that is snowmelt, infiltration, and evaporation are separated to some extent but the algorithms will be calibrated with reference to the input-output relationship e.g. Stanford Water shed Model (SWM), Hydrological Simulation Model (HBV) (Bergström, 1976), Model Trees (MT) (Quinlan, 1992) and Least Square Support Vector Machines (LSSVM) (Suykens et al., 2002). Third type is called physically based or white box. These models are based on the mathematical-physics equations of mass and energy transfer of the river basin which intends to minimize the need of calibration by using the watershed characteristics as the model parameters, e.g. System Hydrologic Europeen (SHE) (Abbott et al., 1986), Institute of Hydrology Distributed Model (IHDM) (Beven and Kirkby, 1979) and the Thales (Grayson et al., 1992). A code such as TOPMODEL (Beven et al., 1987).
Scope and objectives of the study
The main objective of this study was to develop an ANN and LGP models which serve as the benchmarks for an integrated Indian catchments. To achieve this objective, the area selected for the present study was upper Krishna Basin situated on western regions of Maharashtra, India, and lies between latitude 13° 07 ꞌN and 19° 20’ N and longitudes 73° 22’ E and 81° 10’ E. The details of the research carried out by many researchers worldwide are mentioned in subsequent paragraph.
In the past decades, artificial intelligent data driven technique such as ANN, was used to model a wide range of the hydrological processes as they are having ability to model the nonlinear systems very efficiently (Tokar and Johnson, 1999; Thirumalaiah and Deo, 2000; Chang et al., 2002; Sivakumar et al., 2002; Zhang and Chiew, 2009; Googhari et al., 2010). These approaches are developed without taking directly the account of the physical laws underlying the hydrological process and the models were developed only by reusing the information from the hydrological time series (De Vos and Rientjes, 2005; Jothiprakash and Magar, 2012) considered ANFIS models for developing the lumped data rainfall-runoff relationships by considering monthly data and for an intermittent runoff system of Kanand River in Maharashtra State India as a case study. Charhate and Kote (2009) used ANN and Genetic Programming to predict reservoir inflow for Koyana Reservoir of Krishna River basin. They demonstrated the capability of prediction of reservoir inflow in the catchment for weekly and monthly values. Kote and Jothiprakash (2009) identified the performance of ANN’S time lagged recurrent networks (TLRN) with time delay, gamma and laguarre as their memory structure for predicting the seasonal (June– October) reservoir inflow with a monthly time step for Pawana reservoir, of the upper Bhima River Basin, in India. Kote and Jothiprakash (2009) studied the performance of TLRN with AR, ARMA and ARIMA for intermittent reservoir in series using monthly time step for Yadgaon Reservoir in Upper Bhima River Basin India. Mandal and Jothiprakash (2012) applied artificial neural networks (ANNs) to predict the next time step rainfall using lagged time series of observed rainfall data of long term at Koyna Dam, Maharashtra, India.
Even though ANNs are having various good features, still they are suffering because of the limitations such as difficulty in selecting the appropriate training algorithm as well as time consuming efforts for developing the structure. In spite of this limitation there is some scope still for optimizing specific parameters of the network by finding the structure of ANN and training algorithm. To achieve robust learning from the given set of patterns, various kinds of neural networks mechanism are explored in the past. Very few researchers have used Time-Lag Recurrent Neural Network (TLRN and Jordan Eleman network for developing the models, hence attempt has been made to develop the model using TLRN and Jordan Eleman networks of ANN to the present study area. The neural network developed by Neuro solutions is used to develop the models in this work.
In recent days to overcome the drawbacks of the conventional methods certain new techniques such as AI based Artificial Neural Networks (ANN) and Linear Genetic Programming (LGP). GP models are used by many researchers (Londhe and Charhate, 2010; Charhate and Kote, 2009; Jothiprakash et al., 2009; Patel and Ramachandran, 2015) for different basins in Maharashtra as compared to LGP and there is the potentiality of LGP models to further explore different catchments of the Krishna Basin, Maharashtra, India.
LGP models are based upon Automatic Induction of Machine codes by Genetic Programming (AIMGP) and the fitness of LGP is evaluated by Mean Square Error (MSE). Developing of the LGP models was done by the software Discipulus (Francone, 2004).
GP is relatively a new technique based upon Darwin’s natural theory of evolution. Koza (1992) has developed a general method for the induction of symbolic computer programs. The method can be applied to any problem for which a "fitness function" can be defined. This function determines how good a particular program is at solving a given task. Using techniques from genetic algorithms, GP discovers solutions without the need for pre-specifying the size or structure of the program. Genetic programming is a form of inductive machine learning. It evolves a computer program for performing an underlying process as defined by a set of training sample (Whigham and Crapper, 2001). The concept of GP was introduced by (Koza, 1992) and in this the programs are represented as tree structures and expressed in the LISP (List Processing (programming language / lots of Infuriating and Silly Parenthesis) as it is a functional programming language (Babovic and Keijzer, 2000; Brameier and Banzhaf, 2001; Guven, 2009). Generally GP can be considered as an application to solve complex nonlinear problems because its solution describes the input-output relationship. Recently, LGP has emerged a subset, which represents the graph based upon functional structure. It evolves the programs in an imperative programming language (C/C++) and hence it is termed as Linear Genetic Programming (Brameier and Banzhaf, 2001). In LGP the name “linear” refers to the structure of the imperative program representation and it does not stand for functional genetic programs and hence LGP represents highly nonlinear solutions in this context (Brameier and Banzhaf, 2001; Guven, 2009).In LGP, maximum size of the program is usually restricted to avoid over growing of programs without any conditions (Brameier, 2004).LGP is having its main advantage of producing the models that build the understandable structure which mentions that LGP models will exhibit a great potential to prioritize and screen the input variables. In LGP one can involve different parameters such as its population size, rate of mutation, crossover rate, functional set, homogenous crossover rate, program size and number of demes.
From the literature review, it can be observed that many researchers have used only rainfall (P) data to predict the run-off (Q). Few studies have used the inclusion of climatic parameters to decide upon the maximum accuracy which describes the phenomena of rainfall-runoff process in order to estimate runoff. Hence this study uses both hydrological data and climatic data as variables to describe the physical phenomena of the rainfall-runoff process, in order to estimate runoff (Q). Also the meteorological parameters are added to the input to examine the accuracy of the model and inclusion of such parameters to decide upon the maximum accuracy.
Study area and data
The area selected for the present study was Upper Krishna basin located in the western regions of Maharashtra, India lying between latitudes 13° 07' N and 19° 20' N and longitudes 73° 22' E and 81° 10' E. The location of the gauge discharge site along with the location of rain gauge stations in the catchment is shown in Figures1 to 5. The average annual rainfall in the Krishna Basin is 784mm. The South west monsoon sets in the middle of June and withdraws during mid of October. About 90% of the rainfall occurs during the monsoon period of which more than 70% of the annual rainfall occurs during July, August and September.
The observations of daily rainfall and runoff values, and the values of meteorological parameters such as pan evaporation, wind speed, humidity, and minimum and maximum temperatures pertaining to all catchments for the years 2002-2010 were obtained from the Hydrological Data Center Nasik, Maharashtra, India.
Model development
The model building here involved mixing the entire data base for the collected hydrological and meteorological parameters of the study area. Data for training was the data of the four catchments amongst the data sets of five catchments available for all 9 years and for testing the entire data that was available in the individual catchment. Data usage and parameters considered for developing model based on combined data and evaluating on the individual catchment are mentioned in Table 1.The models developed by considering various options are given in Table 2. Model 1 was developed considering average rainfall of all rain gauge stations in the catchment and models 2 was developed considering distributed rainfalls at the rain gauge stations and while developing model 3 one by one meteorological parameters were added along with the distributed rainfalls as input to see the accuracy of the model. The data division for ANN and LGP model was kept for training and not testing.
In building the various models by considering this method care was taken to vary the training data set from the total available set depending upon the availability of data set for testing the respective catchments so that testing the developed model can be done for the individual catchment. Large numbers of trials were conducted. The time series plot and scattered plot between observed and predicted values are drawn to judge for qualitative analysis. As discussed above combined data base of four catchments and estimating the runoff values of remaining catchment the models are developed. The following training testing options are considered based on the catchment size. The model methodology used is same as discussed in previous section, that is, Model 1, Model 2, and Model 3.and the training testing pattern is shown in Table 3.
Performance indicators
The performances of the developed models using ANN and the LGP tools are evaluated by considering the performance evaluation indicators such as Correlation Coefficient (R), Root Mean Square Error (RMSE), and Mean Absolute Error (MAE) using the equations as mentioned below from Equations 1 to 3.
For the estimation of runoff various ANN models were developed based on input, number of hidden layers, neurons in hidden layers and activation function. Using the available data set and architecture the model was developed by changing the number of input parameter, number of hidden layers and number of hidden nodes. The models architecture for Shivade, Shigaon, Gudhe, Amble and Belwadi catchment consists of a layer with 1, 18, 23; 1, 9, 14; 1, 4, 9; 1, 3, 8 and 1, 2, 7, respectively as input parameters with 1 hidden layer and an output layer. Many trials were carried out to decide the number of hidden layers. Models with various combination of training algorithm and transfer functions were trained till the error reached minimum. The model was tested for estimation on unseen data to see the performance of the model. The LGP models that are developed are based on the selection of various control points, that is, fitness function, in terms of mean square error, initial population size, mutation frequency (95%), and the cross-over frequency (53%).
The software Discipulus, designed by AIM Learning and RML Technologies, Inc., Littleton, Colorado, U. S. was used to develop the LGP models. All the forecasting models that are developed were tested for nine years of data that is available in the respective catchments and the evaluation with reference to qualitative and quantitative was done by means of Correlation coefficient (R) between the observed and predicted values and plotting scattered plots between the same. Root Mean Square Error (RMSE) was used to measure the differences between value (Sample and population values) predicted by a model and the values actually observed. Mean Absolute Error (MAE) was used to measure the accuracy of model with respect to the eventual outcomes. Number of trials was considered for developing the models. Their performances are discussed below. The one which showed better performances is considered. The results are tabulated in Tables 3 to 7.

Observations from Table 3 indicate LGP models for all 3 models developed using LGP tool have good performances. Model 1 in comparison with ANN is having correlation coefficient of 0.91 and 0.92 and keeping all the performance evaluation measures low. Amongst them Model 3 where meteorological parameters are added to distributed rainfalls performed well having correlation coefficient of 0.92, indicating the effect of meteorological parameters on the predicted discharges. The time series plot and the scatter plot for the combined data between the estimated and observed values of model 3 are shown in Figures 6 and 7 and confirmed the observations.
The performance of models developed using ANN and LGP tools was fairly equal in all aspects. Even though both the tools have over predicted its values, the models developed by considering LGP tool has little bit over predicted its peak value of discharges and it has captured almost all the peaks for lower and upper value as compared to ANN tool.
Thus for Shivade catchment models, the LGP tool performed well in terms of accuracy of predictions and in the situation of extreme events. However ANN tool seems to perform marginally well, because of the splitting criteria of the input and more over ANN also suffers from the drawback of not predicting extreme events unless they are trained for the similar extreme events. Moreover, the correlation coefficient of LGP tool models was increased after inclusion of meteorological parameters indicating the effect of meteorological parameters on the observed values of discharges. This might be because of the larger size and shape of the catchment. Hence, it clearly indicates characteristics of the catchment play an important role in deciding the performance of models. The performance of LGP was good as compared to ANN with a reason that the models developed using LGP provide inherent functional relationship explicitly over other technique like ANN. Moreover in LGP, the input and target variables as well as functional sets are defined initially and learning method finds both optimal structure of the model and its coefficients. LGP approach is also having the ability to automatically select input variables that are beneficial in model developing and discards those that do not contribute, as such it reduces substantially the dimensionality of the input variables.
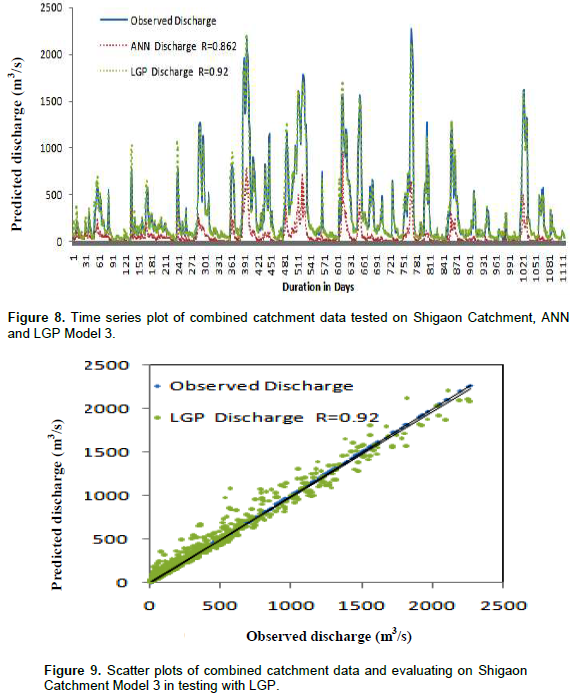
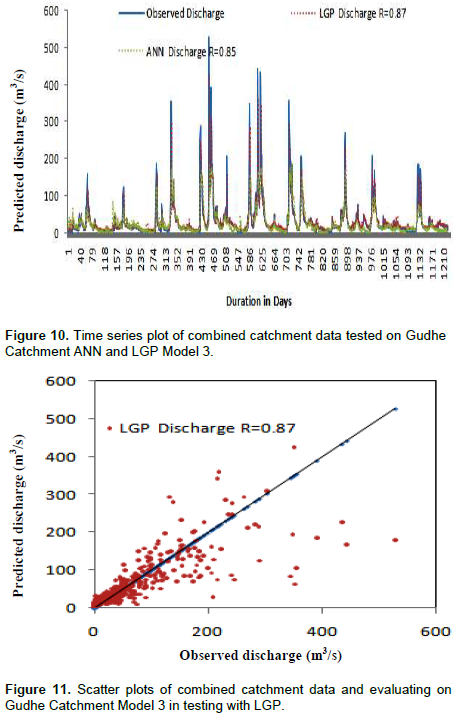
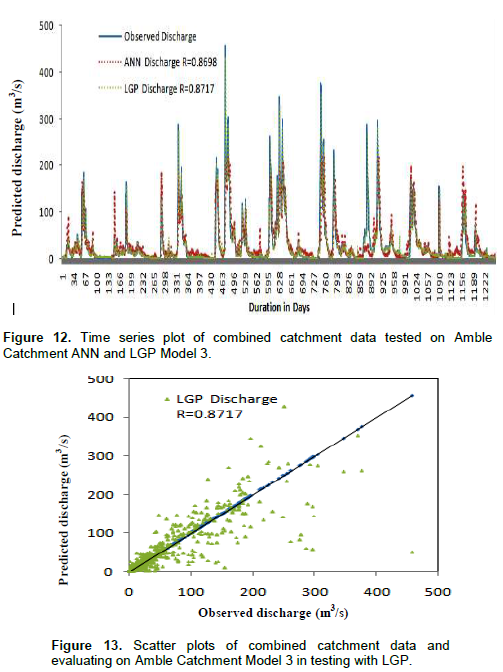
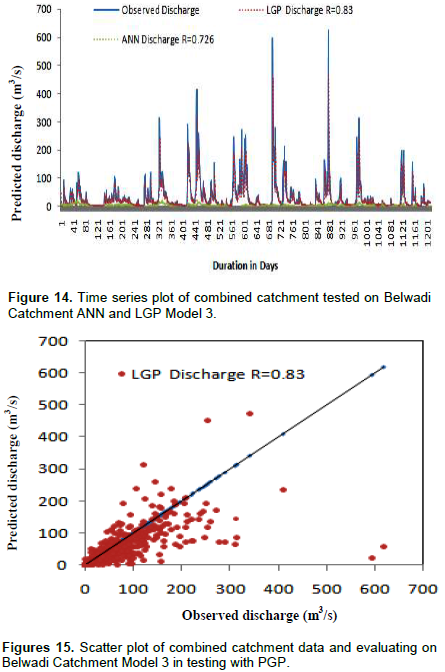
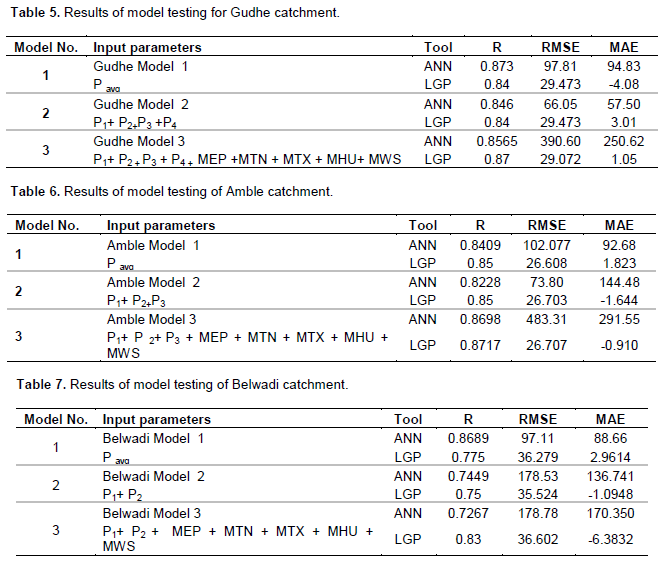
Similar models were developed for the remaining catchments namely Shigaon, Gudhe, Amble and Belwadi. The models were developed keeping in mind the variation in catchment area. The results obtained are shown in Table 4 for Shigaon catchment, Table 5 for Gudhe catchment, Table 6 for Amble catchment and Table 7 for Belwadi catchment and the time series plot and scatter plot are shown in Figures 8 and 9 for Shigaon catchment, Figures 10 and 11 for Gudhe catchment, Figures 12 and 13 for Amble catchment, Figures 14 and 15 for Belwadi catchment respectively.
From Tables 4 to 7 and Figures 8 to 15 it confirms that combined catchment data model is working fine for all the catchments. The combined catchment data model has shown considerably good performance with addition of meteorological data and consistency was maintained.
From the above results, it can be seen that combined catchment data base models developed on catchment area wise and mixing of data is a substitute in case the data from any catchment is missing and is termed as a robust model. Also, it was observed that the performance in testing the models the large catchment areas showed better results as observed in model performance criteria.
The main objective of this study was to develop an ANN and LGP models which serves as the benchmarks for integrated Indian catchments and to present an informative comparison of the data driven techniques viz. ANN and LGP for estimation of runoff for the study area of Shivade, Shigaon, Gudhe, Amble and Belwadi catchments of Krishna River Basin. In comparing the performance evaluation of these data driven techniques it reveals that both the models have performed reasonably well. However, the performance of LG.P model found to be much better as compared to ANN for the models in which only rainfalls are considered as input parameters for estimating the discharges. The inclusion of meteorological parameters was also studied along with characteristics of the terrain. Hence, an attempt was made to develop the models taking both rainfall and meteorological parameters as input parameters in estimating discharges. For all the catchments, the combined catchment data model has shown considerably good performance with addition of meteorological data and consistency was maintained. The performance of LG.P was good in comparison with ANN for estimating the discharges. It can also be seen from time series that LG.P models have quite well estimated the peak values of discharges. It is observed that the LG.P model is much more efficient than either of the other models for estimating discharges of the streams. It can also be mentioned that, the results of the model are influenced by the data variability. It is noteworthy that the negative inflow values are due to the noise and uncertainty of the data since the observed daily inflows are measured using automatic rain gauges. The models developed by mixing the data of the catchments can be a substitute in case the data of one of the catchment is missing and can be termed as robust model also whenever there is no information of the meteorological parameters. Models 1 and 2 for all the catchments can be treated as an addition models. For all the catchments, the effect of characteristics of the catchment and the influence of the meteorological parameters were observed in predicting the runoff as discussed above. LGP models performances were found to be good in comparison with ANN because it has captured all the lower and higher values of peak discharges and has kept all performance evaluation errors very low in various conditions. The study carried out here can be extended to various catchments in other part of the world to see the robustness of the models.
The authors have not declared any conflict of interests.
REFERENCES
|
Abbott MB, Bathurst JC, Cunge JA, O'Connell PE, Rasmussen J. (1986). An introduction to the Europeen hydrological system – Syst'eme Hydrologique Europeen, SHE, 1: History and philosophy of a physically-based, distributed modelling system. J. Hydrol. 87:45–59.
Crossref
|
|
|
|
Babovic V, Keijzer M (2000). Genetic programming as model induction engine. J. Hydro inf. 2(1):35-60.
|
|
|
|
|
Bergström S (1976). Development and application of a conceptual runoff model for Scandinavian catchments. SMHI report, Nr RHO 7.
|
|
|
|
|
Beven KJ, Calver A, Morris EM (1987). The Institute of Hydrology distributed model. Institute of Hydrology Report 98, Wallingford, UK.
|
|
|
|
|
Beven KJ, Kirkby MJ (1979). A physically based variable contributing area model of basin hydrology. Hydrol. Sci. Bull. 24:43-69.
Crossref
|
|
|
|
|
Brameier M, Banzhaf W (2001). Evolving teams of predictors with linear genetic programming. Genet. Program. Evolvable Mach. 2(4):381-407.
Crossref
|
|
|
|
|
Brameier M (2004). On Linear Genetic Programming University of Dortmund, PhD thesis.
|
|
|
|
|
Chang FJ, Chang LC, Huang HL (2002). Real-time recurrent learning neural network for stream-flow forecasting. Hydrol. Process. 16:2577-2588.
Crossref
|
|
|
|
|
Charhate SB, Kote AS (2009). Seasonal reservoir inflow prediction using advance data driven method. J. Appl. Hydrol. 22(2):76-83.
|
|
|
|
|
Googhari SK, Huang YF, Ghazali AHB, Shui LT (2010). Neural Networks for Forecasting Daily Reservoir Inflows. Pertanika J. Sci. Technol. 18(1):33-41.
|
|
|
|
|
Grayson RB, Moore ID, Mc Mahon TA (1992). Physically based hydrologic modelling. Water Resour. Res. 28(10):2639-2658.
Crossref
|
|
|
|
|
Guven A (2009). Linear genetic programming for time-series modelling of daily flow rate. J Earth Syst. Sci. 118(2):137-146.
Crossref
|
|
|
|
|
Haykin S (1994). Neural Networks: a comprehensive foundation. MacMillan, New York. Hydrology 87:45-59.
|
|
|
|
|
Jain A, Kumar AM (2007). Hybrid neural network models for hydrologic time series forecasting. J. Appl. Soft. Comput. 7(2):585-592.
Crossref
|
|
|
|
|
Jothiprakash V, Magar RB, Sunil K (2009). Rainfall-runoff models using Adaptive Neuro-Fuzzy Inference System (ANFIS) for an intermittent river. Int. J. Artif. Intell. 3(A09):1-23.
|
|
|
|
|
Jothiprakash V, Magar RB (2012). Multi-time-step ahead daily and hourly intermittent reservoir inflow prediction by artificial intelligent technique using lumped and distributed data. J. Hydro. 450-451:293-307.
Crossref
|
|
|
|
|
Kote S, Jothiprakash V (2009). Monthly Reservoir Inflow Modeling using Time Lagged Recurrent Networks. Int. J. Tomogr. Simul. 12(F09):64-84.
|
|
|
|
|
Koza JR (1992). Genetic Programming: on the Programming of Computers by Means of Natural Selection. The MIT Press, Cambridge, MA.
|
|
|
|
|
Londhe S, Charhate S (2010). Comparison of data- driven modelling techniques for river flow forecasting. Hydrol. Sci. J. 55(7):1163–1174.
Crossref
|
|
|
|
|
Mandal T, Jothiprakash V (2012). Short-term rainfall prediction using ANN and MT techniques. ISH J. Hydraulic Eng. 18(1):20-26.
Crossref
|
|
|
|
|
De Vos NJ, Rientjes THM (2005).Constraints of ANNs for rainfall-runoff modelling. Hydrol. Earth Syst. Sci. 9:111–126.
Crossref
|
|
|
|
|
Patel SS, Ramachandran P (2015). A comparison of machine learning techniques for Modelling River flow time series: the case of Upper Cauvery River Basin. Water Res. Manage. 29:589–602.
Crossref
|
|
|
|
|
Quinlan JR (1992). Learning with continuous classes. In: Proc. AI'92 (Fifth Australian Joint Conf. on Artificial Intelligence. World Scientific, Singapore. pp. 343-348.
|
|
|
|
|
Sivakumar B, Jayewardene AW, Fernando TMKG (2002). River flow forecasting: use of phase-space reconstruction and artificial neural networks approaches. J. Hydrol. 265(1-4):225-245.
Crossref
|
|
|
|
|
Suykens JAK, De BJ, Lukas L, Vandewalle J (2002). Weighted Least Squares Support Vector Machines: Robustness and Sparse Approximation. Neuro comput. 48(1-4):85-105.
Crossref
|
|
|
|
|
Thirumalaiah K, Deo M (2000). Hydrological Forecasting Using Neural Networks. J. Hydro. Eng. 5(2):180-189.
Crossref
|
|
|
|
|
Todini E (1998). Rainfall-runoff modelling - past, present and future. J. Hydrol. 100:341-352.
Crossref
|
|
|
|
|
Tokar AS, Johnson PA (1999). Rainfall-runoff modelling using artificial neural networks. J. Hydrol. Eng. ASCE 4(3):232-239.
Crossref
|
|
|
|
|
Whigham PA, Crapper PF (2001). Modelling Rainfall–Runoff using Genetic Prog. Math. Comput. Model. 33 (6-7):707-721.
Crossref
|
|
|
|
|
Zhang Y, Chiew FHS (2009). Relative merits of different methods tor runoff prediction in ungauged catchments. Water Resour. Res. 45 W:07412.
|
|