Full Length Research Paper

ABSTRACT
INTRODUCTION
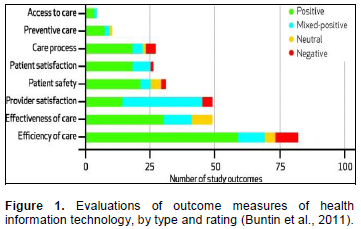
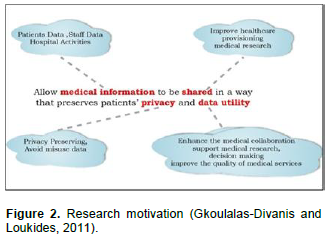
RELATED WORKS
COLLABORATION HEALTHCARE INFORMATION BASED ON PRIVACY PRESERVATION
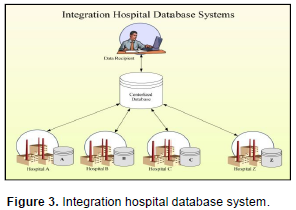
STATE-OF-THE-ART PRIVACY PRESERVING
PRIVACY PRESERVATION AND TECHNICAL CONTRIBUTION
PRIVACY PRESERVATION MODELS
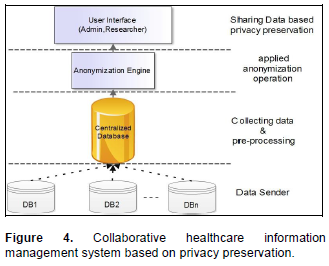
CONCLUSION
CONFLICT OF INTEREST
REFERENCES
| Act A (1996). Health insurance portability and accountability act of 1996. Public Law, 104, 191. | ||||
|
Aggarwal CC, Philip SY (2008). A general survey of privacy-preserving data mining models and algorithms: Springer. Crossref |
||||
|
Aggelidis VP, Chatzoglou PD (2009). Using a modified technology acceptance model in hospitals. International J. Med. Informatics. 78(2):115. Crossref |
||||
|
Ahmed NS, Yasin NM (2012). Improvement the Cooperation Feature in Distributed Healthcare Information Systems Based on the Fractal Approach: An Empirical Study. Adv. Mater. Res. 463:861-867. Crossref |
||||
|
Ammenwerth E, Gräber S, Herrmann G, Bürkle T, König J (2003). Evaluation of health information systems—problems and challenges. Int. J. Med. Inf. 71(2):125-135. Crossref |
||||
| Anshari M, Almunawar MN (2012). Evaluating CRM implementation in healthcare organization. arXiv preprint arXiv: 1204:3689. | ||||
| Aramaki E, Imai T, Miyo K, Ohe K (2006). Automatic deidentification by using sentence features and label consistency. | ||||
|
Arora NK (2003). Interacting with cancer patients: the significance of physicians' communication behavior. Soc. Sci. Med. 57(5):791-806. Crossref |
||||
|
Barak B, Chaudhuri K, Dwork C, Kale S, McSherry F, Talwar K (2007). Privacy, accuracy, and consistency too: a holistic solution to contingency table release. Paper presented at the Proceedings of the twenty-sixth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems. Crossref |
||||
| Bayardo RJ, Agrawal R (2005). Data privacy through optimal k-anonymization. | ||||
| Biafore S (1999). Predictive solutions bring more power to decision makers. Health Manage. Technol. 20(10):12. | ||||
|
Blumenthal D (2009). Stimulating the adoption of health information technology. New Engl. J. Med. 360(15):1477-1479. Crossref |
||||
|
Buntin MB, Burke MF, Hoaglin MC, Blumenthal D (2011). The benefits of health information technology: a review of the recent literature shows predominantly positive results. Health Affairs, 30(3):464-471. Crossref |
||||
|
Byun J-W, Bertino E, Li N (2005). Purpose based access control of complex data for privacy protection. Paper presented at the Proceedings of the tenth ACM symposium on Access control models and technologies. Crossref |
||||
| Campan A, Truta T (2009). Data and structural k-anonymity in social networks. Privacy, Security, and Trust in KDD. pp. 33-54. | ||||
|
Chen L, Yang J-J, Wang Q, Niu Y (2012). A framework for privacy-preserving healthcare data sharing. Paper presented at the e-Health Networking, Applications and Services (Healthcom), 2012 IEEE 14th International Conference on. Crossref |
||||
|
Chen L, Yang JJ, Wang Q, Niu Y (2012). A framework for privacy-preserving healthcare data sharing. Paper presented at the e-Health Networking, Applications and Services (Healthcom), 2012 IEEE 14th International Conference on; 01/2012. Crossref |
||||
| Chiu C-C, Tsai C-Y (2007). A k-anonymity clustering method for effective data privacy preservation. Advanced Data Mining and Applications. pp. 89-99. | ||||
| Christy T (1997). Analytical tools help health firms fight fraud. Insurance and Technology, 22(3):22-26. | ||||
| Clifton C, Atallah M (2007). Collaborative Research: ITR: Distributed Data Mining to Protect Information Privacy. | ||||
|
Clifton C, Kantarcioǧlu M, Doan A, Schadow G, Vaidya J, Elmagarmid A, Suciu D (2004). Privacy-preserving data integration and sharing. Paper presented at the Proceedings of the 9th ACM SIGMOD workshop on Research issues in data mining and knowledge discovery. Crossref |
||||
| Dalenius T (1977). Towards a methodology for statistical disclosure control. Statistik Tidskrift, 15(429-444):2-1. | ||||
|
Dean BB, Lam J, Natoli JL, Butler Q, Aguilar D, Nordyke RJ (2010). Use of Electronic Medical Records for Health Outcomes Research: A Literature Review. Med. Care Res. Rev. 66(6):611-638. Crossref |
||||
| DIRECTIVE HAT (1997). Council Directive 97/43/Euratom of 30 June 1997 on health protection of individuals against the dangers of ionizing radiation in relation to medical exposure, and repealing Directive 84/466/Euratom. Official J. No. L, 180(09/07):0022-0027. | ||||
|
El Emam K, Arbuckle L, Koru G, Eze B, Gaudette L, Neri E, Gluck J (2012). De-identification methods for open health data: the case of the Heritage Health Prize claims dataset. J. Med. Internet Res.14(1). Crossref |
||||
|
El Emam K, Dankar FK (2008). Protecting privacy using k-anonymity. J. Am. Med. Inf. Assoc. 15(5):627-637. Crossref |
||||
|
El Emam K, Dankar FK, Issa R, Jonker E, Amyot D, Cogo E, Vaillancourt R (2009). A globally optimal k-anonymity method for the de-identification of health data. J. Am. Med. Inf. Assoc. 16(5):670-682. Crossref |
||||
| El Emam K, Fineberg A (2009). An overview of techniques for de-identifying personal health information. Access to Information and Privacy Division of Health Canada. | ||||
| El Emam K, Jonker E, Fineberg A (2011). The Case for De-identifying Personal Health Information. | ||||
|
Ernstmann N, Ommen O, Neumann M, Hammer A, Voltz R, Pfaff H (2009). Primary care physician's attitude towards the GERMAN e-Health Card Project—Determinants and Implications. J. Med. Syst. 33(3):181-188. Crossref |
||||
| Fried B, Carpenter WR, Deming WE (2011). Understanding and improving team effectiveness in quality improvement. McLaughlin and Kaluzny's Continuous Quality Improvement in Health Care, P. 117. | ||||
|
Fung B, Wang K, Wang L, Hung PCK (2009). Privacy-preserving data publishing for cluster analysis. Data and Knowledge Engineering, 68(6):552-575. Crossref |
||||
|
Fung BCM, Wang K, Chen R, Yu PS (2010). Privacy-preserving data publishing: A survey of recent developments. ACM Comput. Surv. 42(4):1-53. Crossref |
||||
|
Fung BCM, Wang K, Chen R, Yu PS (2010). Privacy-Preserving Data Publishing: A Survey of Recent Developments. Acm Computing Surveys, 42(4). Crossref |
||||
|
Gaboury I, Bujold M, Boon H, Moher D (2009). Interprofessional collaboration within Canadian integrative healthcare clinics: Key components. Soc. Sci. Med. 69(5):707-715. Crossref |
||||
| Gardner J, Xiong L (2008). HIDE: An integrated system for health information de-identification. | ||||
|
Gardner J, Xiong L (2009). An integrated framework for de-identifying unstructured medical data. Data and Knowledge Engineering, 68(12):1441-1451. Crossref |
||||
| Gkoulalas-Divanis A, Loukides G (2011). Medical Data Sharing: Privacy Challenges and Solutions. | ||||
| Gkoulalas-Divanis A, Verykiosc VS (2009). An overview of privacy preserving data mining. Crossroads, 15(4):6. | ||||
| Glanz K, Rimer BK, Viswanath K (2008). Health behavior and health education: theory, research, and practice: John Wiley and Sons. | ||||
|
Goldzweig CL, Towfigh A, Maglione M, Shekelle PG (2009). Costs and benefits of health information technology: new trends from the literature. Health Affairs 28(2):w282-w293. Crossref |
||||
| Goryczka S, Xiong L, Fung BC (2013). Secure Distributed Data Anonymization and Integration with m-Privacy. | ||||
|
Hillestad R, Bigelow J, Bower A, Girosi F, Meili R, Scoville R, Taylor R (2005). Can electronic medical record systems transform health care? Potential health benefits, savings, and costs. Health Affairs, 24(5):1103-1117. Crossref |
||||
|
Hripcsak G, Bloomrosen M, FlatelyBrennan P, Chute CG, Cimino J, Detmer DE, Hammond WE (2014). Health data use, stewardship, and governance: ongoing gaps and challenges: a report from AMIA's 2012 Health Policy Meeting. J. Am. Med. Inf. Assoc. 21(2):204-211. Crossref |
||||
| Itani W, Kayssi A, Chehab A (2009). Privacy as a service: Privacy-aware data storage and processing in cloud computing architectures. Paper presented at the Dependable, Autonomic and Secure Computing, DASC'09. Eighth IEEE International Conference on. | ||||
| Jiang W, Clifton C (2006). A secure distributed framework for achieving k-anonymity. The VLDB Journal—The International Journal on Very Large Data Bases, 15(4):316-333. | ||||
|
Jiang, W., and Clifton, C. (2006). A secure distributed framework for achieving k-anonymity. Vldb Journal, 15(4), 316-333. Crossref |
||||
| Jurczyk P, Xiong L (2009). Distributed anonymization: Achieving privacy for both data subjects and data providers Data and Applications Security XXIII (pp. 191-207): Springer. | ||||
|
Kaye R, Kokia E, Shalev V, Idar D, Chinitz D (2010). Barriers and success factors in health information technology: A practitioner's perspective. J. Manage. Market. Healthcare 3(2):163-175. Crossref |
||||
| Koh HC, Tan G (2011). Data mining applications in healthcare. J. Healthcare Inf. Manage. 19(2):65. | ||||
| Kohn LT, Corrigan J, Donaldson MS (1999). To err is human: Building a safer health system. Committee on Health Care in America. Institute of Medicine: Washington (DC): National Academy Press. | ||||
| Kuziemsky CE, O'Sullivan TL, Corneil W (2012). An Upstream-Downstream Approach for Disaster Management Information Systems Design. Paper presented at the Proceedings of the ISCRAM Conference. | ||||
|
Kuziemsky CE, Varpio L (2011). A model of awareness to enhance our understanding of interprofessional collaborative care delivery and health information system design to support it. Int. J. Med. Inf. 80(8):e150-e160. Crossref |
||||
| Lau EC, Mowat FS, Kelsh MA, Legg JC, Engel-Nitz NM, Watson HN, Whyte JL (2011). Use of electronic medical records (EMR) for oncology outcomes research: assessing the comparability of EMR information to patient registry and health claims data. Clin. Epidemiol. 3:259. | ||||
| LeFevre K, DeWitt DJ, Ramakrishnan R (2005). Incognito: Efficient full-domain k-anonymity. | ||||
| LeFevre K, DeWitt DJ, Ramakrishnan R (2006). Mondrian multidimensional k-anonymity. | ||||
| Lezzar F, Zidani A, Atef C (2012). A Collaborative Web-based Application for Health Care Tasks Planning. Paper presented at the ICWIT. | ||||
|
Lu YC, Xiao Y, Sears A, Jacko JA (2005). A review and a framework of handheld computer adoption in healthcare. Int. J. Med. Inf. 74(5):409. Crossref |
||||
|
Ludman EJ, Fullerton SM, Spangler L, Trinidad SB, Fujii MM, Jarvik GP, Burke W (2010). Glad you asked: participants' opinions of re-consent for dbGaP data submission. J. Empirical Res. Human Res. ethics: JERHRE, 5(3):9. Crossref |
||||
|
Makoul G, Curry RH, Tang PC (2001). The use of electronic medical records communication patterns in outpatient encounters. J. Am. Med. Inf. Assoc. 8(6):610-615. Crossref |
||||
| Milley A (2000). Healthcare and Data Mining Using data for clinical, customer service and financial results. Health Manage. Technol. 21(8):44-45. | ||||
|
Morton S, Mahoui M, Gibson PJ (2012). Data anonymization using an improved utility measurement. Paper presented at the Proceedings of the 2nd ACM SIGHIT symposium on International health informatics. Crossref |
||||
| Narayanan A, Shmatikov V (2009). De-anonymizing social networks. Paper presented at the Security and Privacy, 2009 30th IEEE Symposium on. | ||||
|
Neamatullah I, Douglass MM, Li-wei HL, Reisner A, Villarroel M, Long WJ, Clifford GD (2008). Automated de-identification of free-text medical records. Bmc Medical Informatics and Decision Making, 8(1):32. Crossref |
||||
|
Nergiz ME, Clifton C (2007). Thoughts on k-anonymization. Data and Knowledge Engineering, 63(3):622-645. Crossref |
||||
| Neumann RG (2010). Information Extraction. Architect. 2: 05.11. | ||||
|
Nosowsky R, Giordano TJ (2006). The Health Insurance Portability and Accountability Act of 1996 (HIPAA) privacy rule: implications for clinical research. Annu. Rev. Med. 57:575-590. Crossref |
||||
| Organization WH (2010). Country Cooperation Strategy for WHO and Egypt 2010–2014. Cario. | ||||
| Parmar AA, Rao UP, Patel DR (2011). Blocking based approach for classification Rule hiding to Preserve the Privacy in Database. | ||||
|
Qi X, Zong M (2012). An Overview of Privacy Preserving Data Mining. Procedia Environ. Sci. 12:1341-1347. Crossref |
||||
|
Rashid AH, Yasin NBM (2012). Anonymization Approach for Protect Privacy of Medical Data and Knowledge Management. Medical Informatics, Prof. Shaul Mordechai (Ed.), ISBN: 978-953-51-0259-5, InTech. Crossref |
||||
|
Reddy MC, Gorman P, Bardram J (2011). Special issue on supporting collaboration in healthcare settings: The role of informatics. Int. J. Med. Inf. 80(8):541-543. Crossref |
||||
| Ruxwana NL, Herselman ME, Conradie DP (2010). ICT applications as e-health solutions in rural healthcare in the Eastern Cape Province of South Africa. Health Inf. Manage. J. 39(1):17-26. | ||||
| Sacharidis D, Mouratidis K, Papadias D (2010). K-anonymity in the presence of external databases. Knowledge and Data Engineering, IEEE Transactions on, 22(3):392-403. | ||||
| Samarati P (2001). Protecting respondents identities in microdata release. Knowledge and Data Engineering, IEEE Transactions on, 13(6):1010-1027. | ||||
|
Scandurra I, Hägglund M, Koch S (2008). From user needs to system specifications: multi-disciplinary thematic seminars as a collaborative design method for development of health information systems. J. Biomed. Inf. 41(4):557-569. Crossref |
||||
|
Scott RE (2007). e-Records in health—Preserving our future. Int. J. Med. Inf. 76(5):427-431. Crossref |
||||
| Sibanda T, Uzuner O (2006). Role of Local Context in De-identification of Ungrammatical, Fragmented Text. North American Chapter of Association for Computational Linguistics/Human Language Technology (NAACL-HLT). | ||||
| Silver M, Sakata T, Su H-C, Herman C, Dolins SB, O Shea MJ (2001). Case study: how to apply data mining techniques in a healthcare data warehouse. J. Healthcare Inf. Manage. 15(2):155-164. | ||||
| Smith HE (2001). A Context-Based Access Control Model for HIPAA Privacy and Security Compliance. SANS Security Essentials. CISSP. | ||||
|
Sokolova M, El Emam K, Arbuckle L, Neri E, Rose S, Jonker E (2012). P2P Watch: Personal Health Information Detection in Peer-to-Peer File-Sharing Networks. J. Med. Internet Res. 14(4). Crossref |
||||
| Sweeney L (1997). Guaranteeing anonymity when sharing medical data, the Datafly System. Paper presented at the Proceedings of the AMIA Annual Fall Symposium. | ||||
|
Sweeney L (2002a). Achieving k-anonymity privacy protection using generalization and suppression. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 10(05):571-588. Crossref |
||||
|
Sweeney L (2002b). k-anonymity: A model for protecting privacy. International Journal of Uncertainty Fuzziness and Knowledge Based Systems, 10(5):557-570. Crossref |
||||
|
Tassa T, Gudes E (2012). Secure distributed computation of anonymized views of shared databases. ACM Transactions on Database Systems (TODS), 37(2):11. Crossref |
||||
| Tierney WM, Achieng M, Baker E, Bell A, Biondich P, Braitstein P, McKown B (2010). Experience implementing electronic health records in three East African countries. Stud Health Technol. Inf. 160(Pt 1):371-375. | ||||
| Truta TM, Vinay B (2006). Privacy protection: p-sensitive k-anonymity property. Paper presented at the Data Engineering Workshops, 2006. Proceedings. 22nd International Conference on. | ||||
|
Tsui FC, Espino JU, Dato VM, Gesteland PH, Hutman J, Wagner MM. (2003). Technical description of RODS: a real-time public health surveillance system. J. Am. Med. Inf. Assoc. 10(5):399-408. Crossref |
||||
| Vaidya J, Zhu M, Clifton CW (2006). Privacy preserving data mining (Vol. 19): Springer-Verlag New York Inc. | ||||
|
Van Vactor JD (2012). Collaborative leadership model in the management of health care. J. Bus. Res. 65(4):555-561. Crossref |
||||
| Wang B, Yang J (2011). The state of the art and tendency of privacy preserving data mining. | ||||
|
Wang C, Wang Q, Ren K, Lou W (2010). Privacy-preserving public auditing for data storage security in cloud computing. Paper presented at the INFOCOM, 2010 Proceedings IEEE. Crossref |
||||
|
Wang SJ, Middleton B, Prosser LA, Bardon CG, Spurr CD, Carchidi PJ, Sussman AJ (2003). A cost-benefit analysis of electronic medical records in primary care. The Am. J. Med. 114(5):397-403. Crossref |
||||
| Weir CR, Hammond KW, Embi PJ, Efthimiadis EN, Thielke SM, Hedeen AN (2011). An exploration of the impact of computerize | ||||
Copyright © 2024 Author(s) retain the copyright of this article.
This article is published under the terms of the Creative Commons Attribution License 4.0


