Full Length Research Paper

ABSTRACT
In this study, artificial neural networks are suggested as a model that can be ‘trained’ to yield qualitative results out of a huge amount of categorical data. It can be said that this is a new approach applied in educational qualitative data analysis. In this direction, a cascade-forward back-propagation neural network (CFBPN) model was developed to analyze categorical data for determine students’ attitudes. The data were collected using a conceptual understanding test which includes open-ended questions. The results of this study indicate that using CFBPN model in analyzing data from educational research examining attitudes, behaviors, or beliefs may help us obtain more detailed information about the data analyzed and hence about the characteristics of the participants involved.
Key words: artificial neural networks; qualitative data analysis; education; biology
INTRODUCTION
Kellerts’ attitudinal typologies
There have been many studies conducted on attitudes towards nature and living things. Studies by Stephen Kellert have special importance because they proposed a particular systematic for attitudes towards nature. By conducting comprehensive studies Kellert (1996) determined nine basic attitude types and showed that attitudes vary with respect to age (Table 1). Whereas children’s relationship with animals is more of emotional at ages 6-9, they focus on learning about living things at ages 10-13. In later developmental stages ethical/ ecological issues emerge related to living things and their habitat.

Most of the studies conducted based on Kellert’s typologies try to determine in which of the 9 categories participants fall. However, in some instances Kellert (1991) made some additions to the 9 basic attitudes. For instance, in a study related to Japanese society Kellert included naturalistic and theistic attitudes (Kellert, 1991). In some other cases, Kellert preferred to use attitudes with similar properties as grouped (such as naturalistic-ecologistic) (Kellert, 1993b).
Data analyses in educational researches
The majority of the data collected within the scope of researches conducted on social cases such as education rely on quantitative data. In this respect, most commonly used statistical analysis procedures are descriptive statistics, t-test, ANOVA/MANOVA, correlation, regression, and psychometric statistics (Hsu, 2005). The main reason for this is that quantitative data take less time to collect and analyze by using package software. However, results obtained from qualitative analyses provide more in-depth data on subjects and thus considered to be more ‘valuable’ for researchers. In this respect, it is considered that new methods to analyze a large amount of qualitative data in a short span of time with minimal loss are required.
The main reason that encourages us to conduct this study is our persuasion that artificial neural networks have such a huge potential. Customized artificial neural network architectures and training algorithms specific to individual studies are considered to be used in the analyses of qualitative data. For example, in this study, artificial neural networks are suggested as a model that can be ‘trained’ to yield qualitative results out of a huge amount of categorical data.
Artiï¬cial neural networks
Artificial neural networks (ANNs) are mathematical models inspired by biological neural networks contained in human brain. Having similar characteristics to those of biological neural networks (i.e. consistency, flexibility, parallel function, and tolerance to errors, etc.), these systems attempt to learn tasks and determine how they will react to new tasks by means of creating their own experiences through the data obtained by using the predetermined samples (Sagiroglu et al., 2003).
Neural networks can be used to model complex relationship without using simplifying assumptions, which are commonly used in linear approaches. The other advantages of the ANNs are the ability to represent both linear and nonlinear relationships, the ability to learn these relationships directly from the data used, need not take into account a detailed information of structures and interactions in the systems, and they are regarded as ultimate black-box models. At least in some cases if not always, i.e. for prediction using the trained network, the ANN systems are alternative to experimentation and save a lot of time which may have been consumed since experimentation is so difficult and in some cases are impossible. Artificial neurons based on biological model were first defined by McCulloch and Pitts. McCulloch-Pitts (MCP) neuron model is given in Figure 1.

In all neural network models, input values are multiplied by connection weights and then summed up. Summation unit is compatible with the body of biological neuron. It sums up weighted inputs and then gives the net output, such that:
.png)
Input values ( ) are multiplied by weights ( ) assigned to connections and applied to additive function (S) together with a bias value ( ∗ ). Bias value is applied to neuron externally. Output is obtained by application of f activation function to additive function output.
Each input has an effect on output in proportion to weights assigned to connections, and threshold value is independent from system inputs. In case the values of all inputs are equal to 0, the output function is represented as f( ∗ ).
In case of biological neurons, neuron yields to output when input exceeds the activation value. In order to apply this feature in ANNs, an activation function, usually nonlinear, which produces cell output by means of processing net input obtained from additive function, is used. Various activation functions are applied based on the model used. Most commonly used functions are step functions (unipolar and bipolar), linear functions (standard linear, and symmetric piecewise linear), and sigmoid functions (logarithmic sigmoid and tangent sigmoid).
Structures of ANN
ANNs can be analyzed in two separate groups as single-layer and multilayer ANNs, which are determined based on the number of layers in their structures (i.e. network architectures). In a single-layer neural network, neurons represent output layer. Neurons receiving input values are not considered as input layer due to the fact that no calculations are made in this layer. Data received from input layer is calculated in output layer and network output is obtained.
On the other hand, multilayer networks are different from other networks, such that multilayer networks have one or more hidden layers and also weighting is applied in input layer. In multilayer networks, at least one hidden layer ( , ) is represented between output layer ( ) and input layer ( , ) (Fausett, 1994) (Figure 2).

Learning in ANNs
In a neural network, learning can be defined as reaching optimum weight values between neurons, which provides approximation between the output values calculated by output values versus a given input vector set and the expected output values.
A training algorithm is used for learning process and compositions of weights are determined by these algorithms. The objective of the learning process is to obtain an output value with a maximum approximation to the expected output by means of reducing errors using learning algorithms. For this purpose, weights in the system are iterated in each network with an aim to reduce errors. If artificial neural networks have achieved their goal with the input-output pairs, weight values are saved. The process during which weights are constantly iterated until the expected result is achieved is defined as "learning" (Lawrence et al., 1997).
Delta Rule, also applies to this study, is one of the most commonly used learning rules (Sagiroglu et al., 2003). Reducing the discrepancy between the expected output value and the predicted output value of neuron, this learning rule is based on the concept that strengthens and constantly changes input connections. This rule is based on the principle of reducing mean square error by means of changing weight values of the connections and it attempts to reduce errors by means of back propagation from output layer towards input layer. Therefore, Delta Rule is also called back propagation or least mean square learning rule.
Feed forward back-propagation ANNs (FFANN)
In feed forward ANNs, one layer contains some neurons which are connected to those of the following layer. Each connection is weighed. A neuron is described with its own activation level, which is responsible for the propagation of the information from the input layer to the output layer. However, to obtain reliable weights, the neural network must learn about the known input- and output-samples. During the learning process, an error between theoretical and experimental outputs is computed. Thus, the weight-values are modified through an error back propagation process which is executed on several sampling data, until achieving as small error as possible. After this last step, the neural network can be considered as trained and able to be used in calculating other responses to new entries that have never been presented to the network. It is important to emphasize that the learning speed of the neural network depends not only on the architecture but also on the algorithm used (Gallant, 1993; Guney, 1997).
Back-propagation algorithm
Back propagation of errors learning model, first introduced by Rumelhart (1986), is one of the most commonly used models amongst other artificial neural network learning models (Rumelhart, 1986). In back propagation algorithm, learning mechanism is based on iterative gradient descent method which minimizes errors between the expected outputs and the predicted outputs of the network. In learning rule, error calculated in network output is used in the calculation of new values of the weights. Supposing that represents output value of the th neuron in the output of artificial neural network after times of iteration of the training, represents the expected value, and represents the error signal of the neuron, then the calculation of error value is defined by the following Equation:

When an input data is applied to a network, various processes are performed on this data until it reaches output layer. Output obtained as a result of these processes is compared to the expected output and approximation function is defined by the following Equation:
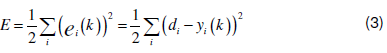
The difference between the calculated values and the expected values is calculated as an error signal for each output node. Based on these error signals, connection weights are rearranged for each neuron. This arrangement allows for convergence of the network to a condition where all data can be coded, and the gradient of weight values is determined by the method of the steepest falling gradient (Rumelhart, 1986), which can be represented by the following Equation:

In the above Equation, η is coefficient of learning. Each iteration process in back propagation algorithm consists of two stages as forward propagation and back propagation. During forward propagation, output values of ANN versus input signals applied to ANN at that time are determined. During back propagation, the previously assigned weights are rearranged on the basis of resulting output errors. Each change of weight in ANN is performed based on the following equation:

For neurons in output layer, is defined as

Whereas, for neurons in hidden layers, it is defined as

is the activation function of neuron. By these definitions, the flow of error signals from output towards input is considered to be similar to the flow of signals forward during forward propagation. Iteration process continues until the error value is reduced to a certain level and therefore training process of the network is completed. Weight values of the connections between layers are obtained from the network upon completion of its training and these values are stored to be used during test process (Yao 1999).
METHOD
Qualitative data obtained from student answers to open-ended questions were used to train and test the ANN model. 80% of this data was used for training of the network and the remaining 20% was used for testing of the network (Hagan et al., 1996). Detailed information and algorithms of ANNs are explained in above section 1.3.
Subjects
The participants included 214 students (127 female and 87 male) who were selected via cluster sampling method (Bogdan and Biklen, 2006) from eight high schools in Izmir, a large city in western Turkey. Schools accepted students from different parts of the city and students varied in terms of socioeconomic status.
Data collection
In this study a conceptual understanding test was used. The test included open-ended questions and was developed by researchers. In addition, to clarify vague concepts and to obtain in-depth information about the topics interviews were conducted with students and teachers. The final version of the test used in this study is presented in Table 2.

Data analyses
The fourth question in the conceptual understanding test was used to train and test our artificial neural network. Students answer this question at two stages. First, they were asked to list the names of 5 living things according to importance. Then, they were asked to explain the criteria they used to write the name of the first living thing as the first on the list.
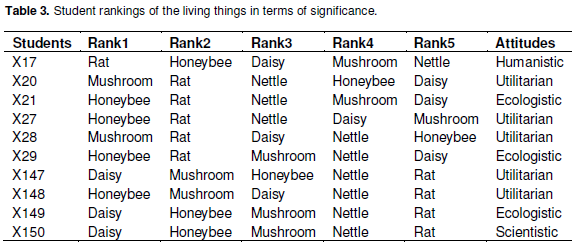
Students’ answers to the 4th question evaluated along with their answers to other questions and their attitudes were tried to determine based on Kellert’s typologies. For example, let’s assume that two students list the names of the living things as the same and both wrote the honeybee first. Let us further assume that one student’s reason to write honeybee first was that “honeybees are living things that have important functions in nature.” The reason put forth by the other student was that “honeybees make honey for us.” In this case, according to Kellert’s typologies first student can be characterized as ‘ecologistic’ and the second as ‘utilitarian.’ All students’ answers were analyzed in this way and the data were tabulated. Some data are presented in Table 3.
Creating CFBPN model
In this study, we developed a cascade-forward back-propagation network (CFBPN) model. The CFBPN model is structurally very similar to the FFANN model. Every neuron at input and hidden layers are connected to each other. In addition, all input layer neurons and output layer neurons have direct connections with each other. While the hidden layer takes data only from the input layer, the output layer takes data from both the input layer and the hidden layer. According to Filik and Kurban (2007) the fact that input layer (independent variables) and the output layer (dependent variables) is connected provides CFBPN model some advantages over the FFANN model in some cases.
To test the proposed ANN model collected data were divided into two groups as training data and test data. Training data were used to develop the ANN model. Test data were not used in training, they were used to verify and test the ANN model.
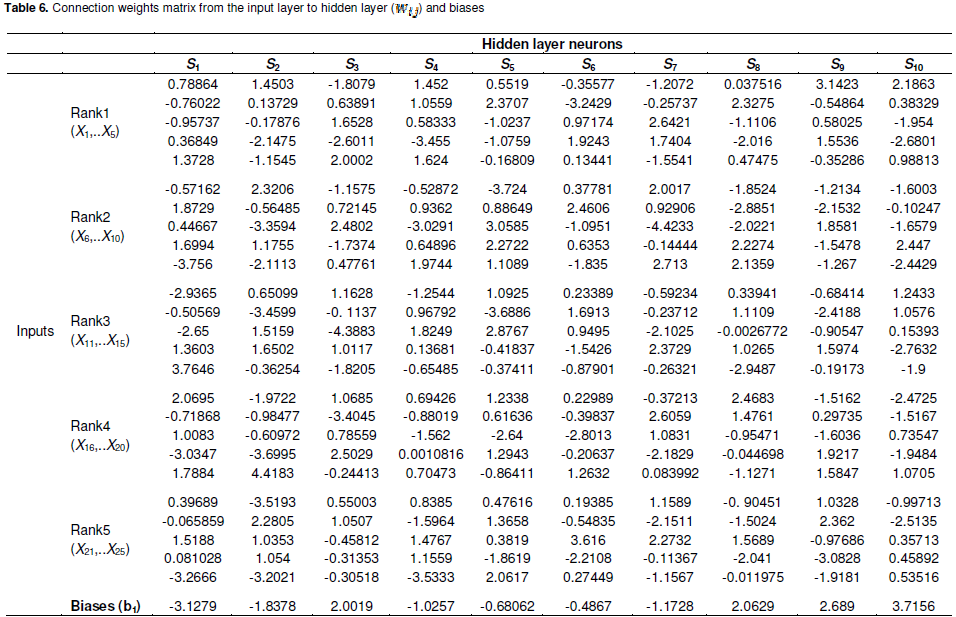
The model started training with the randomly chosen weight matrix. Then, results from the output layer compared to expected results and a back propagation error value is defined. This error value is back propagated in the network and weights were rearranged. This process continued until there is minimum error value or there is no change in weights. In addition, number of neurons hidden layer should have was determined to be able to obtain appropriate results. There is not a definite method of determining the number of neurons hidden layer should have. It has been determined through trial and error depending on researcher experience. The number of neurons in input and output layers is determined according to number of dependent and independent variables. Since listing names of five living things is the independent variable, there are 25 neurons in the input layer to represent this listing. Since there are four attitudinal typology types determined, there are four neurons in the output layer to represent this. Table 4 shows how the data in Table 3 were coded to train our network.

As the set of species contained in the research problem is given to the students in the following sequence as “rat, nettle, mushroom, honey bee, and daisy”, the same sequence has also been used in coding. For each species, a vector containing four ‘0’ and one ‘1’ has been used. Therefore, the code used by a student to list these five species is a vector consisting of 25 bits. For example, when the following sequence as ‘nettle-honey bee-daisy-mushroom-rat’ is coded, (01000) in the first order for nettle, (00010) in the second order for honey bee, (00001) in the third order for daisy, (00100) in the fourth order for mushroom, and (10000) in the fifth order for rat are entered, respectively. In other words, the complete sequence is coded as the following: 0100000010000010010010000. Written in vector notation, it is the input vector: (0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0).
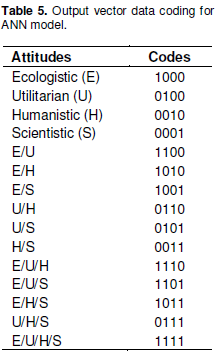
A similar method has been used in coding attitudes (Table 5.). (1000) for ecologist, (0100) for utilitarian, (0010) for humanistic, and (0001) for scientific have been used, respectively. However, a coding method inspired by the studies on rough set conducted by Narli et al. (2010) has been developed for the students who list the species in the same order, however having different attitude characteristics. Therefore, codes have been used in combinations in case of two or more attitudes. For example, the code (1100) has been used in case of ecologist-utilitarian, and the code (1011) has been used in case of ecologist-humanistic-scientific.
In the next stage, the transfer function for each stage must be determined by trial and error approach. In this regards, different types of transfer functions including logarithmic sigmoid, hyper-bolic tangent sigmoid, linear, and radial basis transfer functions were used to ï¬nd the proper transfer function for the proposed neural network (Hagan et al., 1996).
Next, we determined transfer functions necessary for every stage. To determine the most appropriate transfer functions for our model, logarithmic sigmoid (logsig), hyperbolic tangent sigmoid (tansig), linear, and radial basis transfer functions were tried. As a result, logsig (Eq. (8)) and tansig (Eq. (9)) functions were decided as appropriate for the hidden layer and output layer respectively
(Figure 3.).


The CFBPN model used in our study has 25 neurons in input layer, 10 neurons in hidden layer and four neurons in output layer. The model is shown schematically in Figure 4.

RESULTS AND DISCUSSION
First, 184 cases were used for training of the network and30 cases were used for testing the network. According to the results obtained via trial and error approach, optimum number of neurons that hidden layer should have was determined as 10. Therefore, to have a minimum error our network model should have a network architecture as 25x10x4 (Figure 5). The activation (transfer) functions used in hidden and output layers are logsig and tansig respectively.

In addition, the synaptic parameters including weights and biases are given in Tables 6, 7 and 8 which enable any one to reproduce every used data points in the present study.


The network was trained until optimum parameters are obtained (more than 1000 epoch). Then, it was tested using test data. The training and test phases are displayed in Figures 6 and 7 respectively. As a result, there is great consistency between the results our model produced and the expected results.


CONCLUSION
The present study used a CFBPN model approach to an educational research involving qualitative data. It can be said that this is a new approach applied in educational qualitative data analysis. Consequently, the present study has attempted to show the applicability of ANNs in detailed analyses of educational data. The ANNs are utilized mostly in areas such as artificial intelligence (AI), machine learning, pattern recognition, decision support systems, expert systems, data analysis, and data mining.
Kellert (1993a, b) has represented some typologies in binary groups (e.g., utilitarian–dominionistic). However, these groupings occur between typologies that display very similar characteristics. Narli et al. (2010) argued that there may be students who have intermediate attitudes among the typologies identified by Kellert. In this study, it has been showed that CFBPN model can be trained to uncover intermediate attitudes. Moreover, this can be done in much shorter time in this way.
Consequently, the results of this study indicate that using CFBPN model in analyzing data from educational research examining attitudes, behaviors, or beliefs may help us obtain more detailed information about the data analyzed and hence about the characteristics of the participants involved. In addition, precise knowledge about our students’ attitudes and beliefs may prove helpful in curricular and instructional studies.
CONFLICT OF INTERESTS
The authors have not declared any conflicts of interest.
REFERENCES
| Bogdan R, Biklen SK (2006). Qualitative Research for Education: An Introduction to Theories and Methods (5th Ed.). Pearson, New York | ||||
|
Cybenko GV (1989). Approximation by superpositions of a sigmoidal function. Math. Control Signal 2:303–314. Crossref |
||||
| Fausett L (1994). Fundamentals of Neural Networks. Prentice-Hall, New Jersey. | ||||
| Filik UB, Kurban M (2007). A new approach for the short-term load forecasting with autoregressive and artificial neural network models, Int. J. Comput. Int. Res. 3:66–71. | ||||
| Gallant S (1993). Neural Network Learning and Expert systems, MIT Press, Cambridge. | ||||
| Guney K (1997). An introduction to neural networks. UCL Press, London. | ||||
| Hagan M, Menhaj M (1994). Training feed forward networks with the marquardt algorithm. In Proceedings of IEEE Transactions on Neural Networks. 6:989. | ||||
| Hagan MT, Demuth HB, Beale M (1996). Neural network design. PWS Pub., Boston | ||||
|
Hsu T (2005). Research methods and data analysis procedures used by educational researchers. Int. J. Res. Met. Educ. 28:109-133. Crossref |
||||
|
Kellert SR (1991). Japanese perceptions of wildlife. Conserv. Biol. 5:297-308. Crossref |
||||
| Kellert SR (1993a). The biological basis for human values of nature. In: Kellert SR, Wilson EO (eds) The biophilia hypothesis. pp. 42–69. Island Press, Washington DC | ||||
|
Kellert SR (1993b) Attitudes, knowledge, and behavior toward wildlife among the industrial superpowers: United States, Japan, and Germany. J. Soc. Issues 49:53-69. Crossref |
||||
| Kellert SR (1996). The value of life: biological diversity and human society. Island Press, Washington DC | ||||
| Lawrence S et al. (1997) Lessons in neural network training: Training may be harder than expected, In Proceedings of National Conference on Artiï¬cial Intelligence, AAAI-97, pp.540–545, Menlo Park, California | ||||
| Levenberg K (1944). A method for the solution of certain nonlinear problems in least squares, Quart. Appl. Math. 2:164-168. | ||||
|
Narli S, Yorek N, Sahin M Usak M (2010). Can we make definite categorization of student attitudes? A rough set approach to investigate students' implicit attitudinal typologies toward living things, J. Sci. Educ. Tech. 19:456-469. Crossref |
||||
|
Rumelhart D (1986). Learning representations by backpropagation errors. Nature 323:533–536. Crossref |
||||
| Rumelhart D, McClelland J (1986). Parallel Distributed Processing. MIT Press, Cambridge | ||||
| Sagiroglu S et al. (2003). Muhendislikte Yapay Zeka Uygulamalari-I: Yapay Sinir Aglari (in Turkish), Ufuk Yayincilik. | ||||
|
Thompson TL, Mintzes JJ (2002). Cognitive structure and the affective domain: On knowing and feeling in biology. Int. J. Sci. Educ. 24:645-660. Crossref |
||||
| Yao X (1999). Evolving artiï¬cial neural networks. In Proceeedings of the IEEE, 87:1423–1447. | ||||
| Yorek N, Narli S (2009). Modeling of cognitive structure of uncertain scientific concepts using fuzzy-rough sets and intuitionistic fuzzy sets: Example of the life concept, Int. J. Uncertain. fuzz. 17:747-769. | ||||
Copyright © 2024 Author(s) retain the copyright of this article.
This article is published under the terms of the Creative Commons Attribution License 4.0


